AI��Ȩ�����֮�裺���Ϻͺ�����֯
����21���;��ñ������� ���� ʵϰ�� ���� ��������
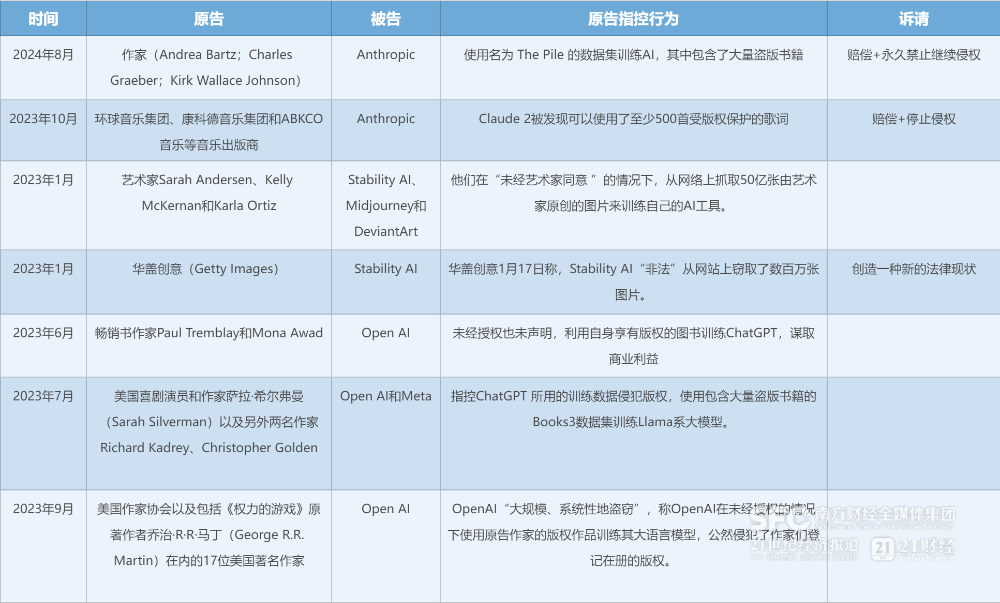
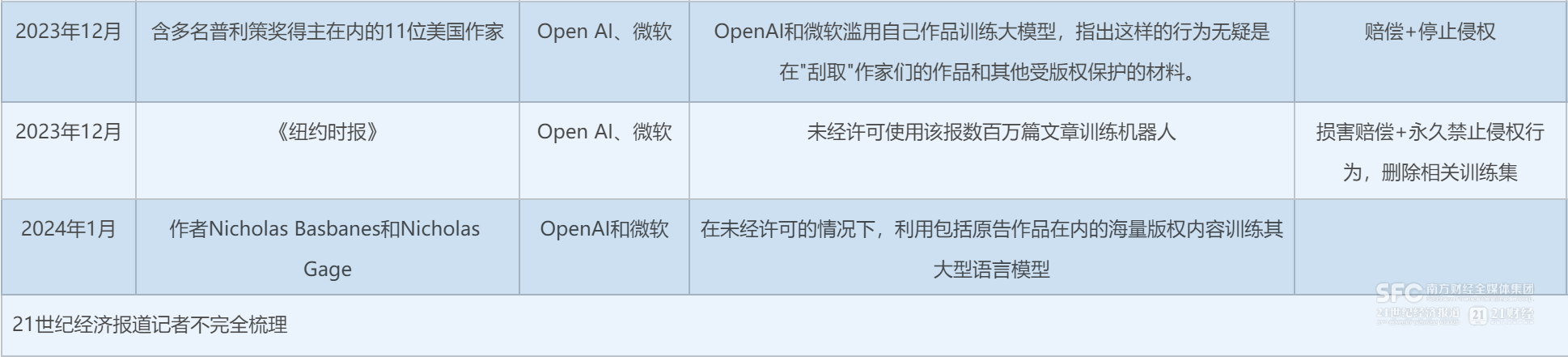
����AI����İ�Ȩս�����ڼ�������������֮�衣���ܣ�һ����OpenAIͷ�ž������ֵ�Anthropic��ָAIѵ����Ȩ�����ߣ���һ������OpenAI�����ƽ���Ȩ��������ӵ��Vogue�ȶ���ʱ����־�Ĺ���֪�����漯�ſ�̩����������ɰ�Ȩ����Э�顣
������Ȩ�����ս����Ȼ�����Ϊ�˹����ܲ�ҵ�Ϲ��������Ŀ��⣬�²�ҵ��300832��������������һ���ǿƼ���˾��ȡ������ѵ�����ϵ�������һ���������ų��������������ֵ��ά����
������ý��ļ���֪ʶ��Ȩ���ܵ���в������Ӧ�ô���Ҫ���⳥����ӵ�С��������ձ�������̩��ʿ���������ż�������˵��
����ͨ��������Ŀǰ�����˹����ܹ�˾����ѵ��AI��Ҫ��Ȩ���ɺ��ѣ�Ը��봽������������Ҳ��˫��֮�佻�����0��Դͷ��
������ս�У�OpenAI�����ƽ������ų�������ĺ�����һ������Ϊ����װ������DZ�ڵ����Ϲ�˾����һ���棬̸£�İ�Ȩ�����ܸ��õ�֧�ž���ҵ����ģʽ��ҪΪ�����Ȩ�Ѽ���ص������û���
��������Ϊ�˹����ܹ�˾�����ų�����ҵ֮������������ĺ���ģʽ������˫���ĺ���Э������վ���
����OpenAI��Ȩ�������������
����8��20�գ�OpenAI���������֪�����漯�ſ�̩���˽��������������ϵ������Э��ʹOpenAI����ChatGPT ������������ SearchGPT ���˹�����������ƽ̨��չʾ�����Ͽ�̩���˵����ݡ�
������̩������OpenAI���������ݿ⣬ΪAIѵ���ṩ�����֡�ͬʱOpenAI�����ʺ�չʾ��̩���˵���Ϣ���û�����ֱ��ͨ��ChatGPT��SearchGPT��������Щ���������Ϣ����֮������
������̩�����ǵ¹���������湫˾�����°�����Vogue������The New Yorker������GQ�� ��֪����־����̩������ϯִ�й��ܡ����棨Roger Lynch����ʾ����������OpenAI�ĺ��������ֲ��������룬ʹ�����ܹ�����������Ͷ�����ǵ����źʹ������
�����������ݺ���Э����OpenAI�����ý�幫˾��ɵ�����Э�顣
������̩���˼��ŵ���ϯִ�й��ܡ����棨Roger Lynch��ǿ�������ֻ��һ����ʼ�����ǽ������ƽ������չ�Ĺ�����Ϊ������ҵ�Ĺ�ƽ���ͺ���������ֱ�����п����Ͳ����˹����ܵ�ʵ�嶼�� OpenAI һ�����������س����̵�Ȩ������
����OpenAI��Ұ�ģ���AI�����зָ�
���������������Ȩ��Ȩ���Ϻ�OpenAIһֱ�ڻ����ƽ������ų�������ĺ�������ȴ�˴εĿ�̩���ˣ������硢Axel Springer���������¿���Dotdash Meredith������ʱ����LeMonde�����ż��š�Prisa Media��ʱ���ܿ���Vox Media �Ⱦ��Ѿ���������OpenAI�ĺ�����Ȩ���С�
���������ǵ�ʹ���ǽ�����ҵ���˹����ܷ��������ؽ����������OpenAI�ơ�
�������������˹���������Ը��Ͷ��������������Ȩ�Ϲ桢�����ų������Ǣ̸�����IJ��dz�̬��
����OpenAI�˾٣�һ������Ϊ����װ������Ϊ�˹�������������λ�õ���ҵ����ע�ȸߣ�����Ҳ�ࡣ21���;��ñ����������֣���ѵ�����ݵİ�Ȩ�����ϣ���������ʮ�������ϣ������漰OpenAI��ռ��һ�롣������ȡ��Ȩ�������ܰ���DZ�ڵ����Ϲ�˾����һ�����ڸ��ٷ�չ����ҵ�����ƺ�������֮�١�
������һ���棬̸£�İ�Ȩ�����ܸ��õ�֧�ž���ҵ��
����OpenAI�뿵̩���˽����е�һ���־��ǣ����伴���Ƴ����������� SearchGPT ��Ʒ��ʹ�ÿ�̩���˵����ݡ�
��������7�£�OpenAI �����Ƴ����˹������������������� SearchGPT������ʵʱ�������Ի���������Ϣ�����Ұ�����Ϣ��Դ�����ӡ�
������ǰ�������˰�ChatGPT������������˵����������ã������׳��֡�����װ��������һ��������˵�˵����������AI����һ���̶��Ͽ��Կ˷���һ�㡣ͨ����AI������Ʒ��ѯ���������ʱ�������Ļظ����ԽDZ����ʽ�ڽ�β���ϲο���Դ���ɵ��ԭ���Ӻ˲���ʵ�ԡ�
������Ҳʹ��AI����Ҳ��ΪAIӦ�õ���ս�����Ƿ����н���3�µı�����ʾ�� AI������Ʒ�ķ�����ռ����24.2%��ȫ���г��ݶ������AI��������ˡ�
���������������ע�ο���ԴҲ���ڰ�Ȩ�Ϲ�����⡣��������ͷ��Perplexity����Ϊ�˹�����ժҪ���ܶ��ܵ����飬��������������ֱ�����������ǵ���Ʒ���������AI�յ���֪��28ҳ����Ȩ��֪����������������Ʒ�ġ�ѧ����������¼�����ĵ�����ժҪ����¼����δ��¼�������ݱ������Ķ�������ͨ����Դ������ת����վ��ȡ��
����OpenAI�İ�Ȩ�������ܱ���������һЩ��Ȩ���ס�OpenAI�ƣ�SearchGPT���������ź�����鹲ͬ�����ġ�OpenAI��ʾ�������̽�ӵ��һ�ֹ���������OpenAI���������г��ַ�ʽ�ķ��������ǿ���ѡ���Լ�����������ѵ��OpenAI��ģ�ͣ�����Ȼ��������������г��֡�
����SearchGPTּ��ͨ�������������ͻ����ʾ�����ӵ������̣������û�������̽�����ϵ����Ӧ������ȷ�ġ�Ƕ��ʽ�����������ú����ӣ������û���֪����Ϣ���Ժδ��������Կ���ͨ��������Դ���ӵIJ�������ʸ�������
����˦���˰�Ȩ�Ϲ�İ�����OpenAIΪ�˸����̿�AI������ҵ��ȥ�������Ӧ�õ���ء�
����̽·�˹����ܹ�˾�����ų������ģʽ
����21���;��ñ����������֣�����OpenAI���ȸ衢MetaҲ�������ų������Ǣ̸���������dz���Զ����OpenAI��
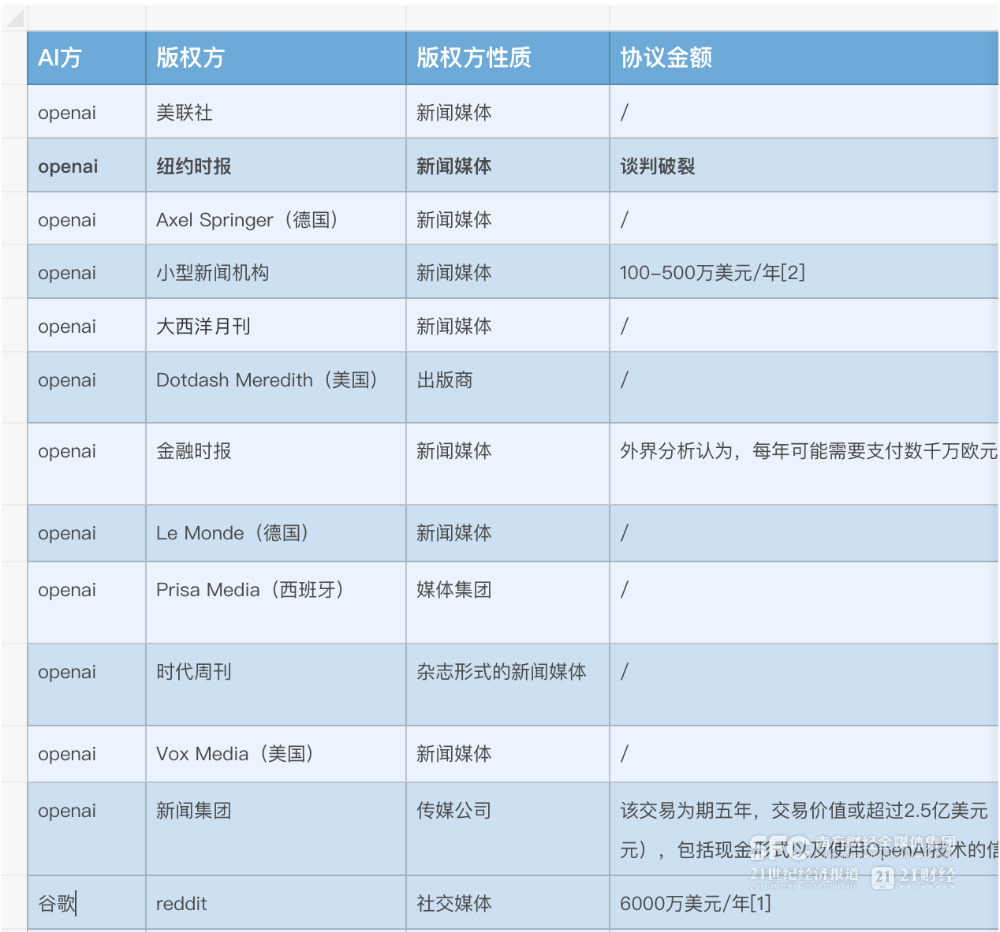
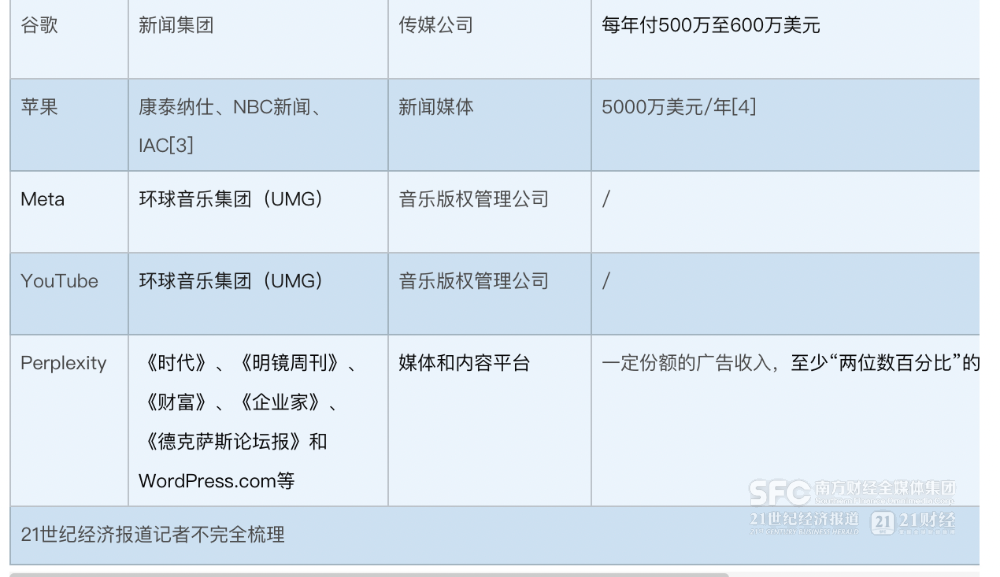
�������ң���ЩǮҲ������Ը�������˹����ܹ�˾���ڷ���ѵ��AI��Ҫ��Ȩ���ɺ��ѡ��ȸ���ȥ��ظ�������Ȩ�ֵ�ʱ���ʾ���������ģ��ѵ�����̵�ÿһ��������ץȡ��Ϣ���������뵽����������ֻ������ĸ�����Ϊ�����ڰ�Ȩ�������У�������Ϊ��������Ȩ������Ҳ�������˾�ϿɵĹ۵㡣
������Ҳ�漰���˹����ܴ�ģ�͵ļ���ԭ�����ϲƺϹ�Ƽ��о�Ժ��21���;��ñ�����ǰ�����ἰ�����˹�����ʱ������֪ʶ��Һ̬�������⣬��Ʒ�ӱ������ˮ�����������������϶�����ģ�ͼ�ס����ͳ�ƹ�ϵ���������ı������� OpenAI��ʾ����ģ�͵�ÿ�����֣���Ȩ�أ���ӳ�˲�ͬ�����ڲ�ͬ����µ�ͳ�ƹ�ϵ�������˷���ָ��ʱ����ģ�͵���Ȩ��Ԥ����һ���ʺ;��ӡ�������ͨ�����ݿ����·��ʰ�Ȩ��Ʒ��Ҳ����ֱ�Ӹ���ճ����Ʒ�����ݡ�
���������顱�ľٶ������϶����˹����ܹ�˾Ҳû�и��ѵĶ�����
����������������������࣬���ų��湫˾���������Ȩ���ڻ���άȨ������Ҳ���˹ٷ��³�������4�£��ȸ���δ����ʹ�÷�����������ѵ��AI��������2.5��ŷԪ��
����ѵ�����ݰ�Ȩ�Ϲ��ڹ������������ӣ�OpenAI�ƽ��İ�Ȩ����һ���̶��ϣ����ڻ�ս����������·��������ģʽ��Ҫ�ǰ�Ȩ�ѣ��������ݴ����ߣ��Լ�����֮��������û���
����Ŀǰͨ��ֱ�Ӳ��������������ϰ�Ȩ��������Ҫ��Ϊ���֣���ǰ��������Ȩ�˵���Ʒ�ڱ�����Ϊѵ������ʱ��ò������º���ͨ���ض������� AI �������ݵ�ѵ������Դ��������Եظ��貹����
������������ǰ�����ļ����ѶȽϵͣ������Խ綨�����IJ�����ȣ��º�ָͨ�������ֶζ�ѵ��������Դ�����ж�Ӧ�İ�Ȩ���������۸������������Ѷ��в����졣
���������ǰ�Ȩ�����е�����ɽ��ŦԼʱ�������ǡ�̸���ˡ��ĵ������ӡ�ȥ��4�¡�ŦԼʱ������ʼ��OpenAI̸�У���ʼ��û�ܴ���κθ�������Э�顣12��27�գ���ŦԼʱ������ʽ��OpenAI���Ϸ�ͥ��ָ������δ������ʹ��������ѵ��AI��Ҫ��е�����ʮ����Ԫ�ķ�����ʵ����ʧ������־�����������ѡ�
���������ںܶ������Ҳ����Ӧ�������û�������磬OpenAI��������ĺ����У���������������ű�����ΪOpenAI�ṩѵ�����ݣ� ������Ҳ�ὫOpenAI �ļ������ϵ�����ҵ���С�
�������������Ƿ����˹����ܹ�˾�����ų�����ҵ֮������������ĺ���ģʽ�أ�̸£���������ų��������ʱ�Ե������ǣ������Ժ����˪���Դ˴��뿵̩���˵ĺ������������ٷ���������Ϊ��SearchGPT ���˹��������������������ṩ�Ի�ʽ��Ӧ�����Ǵ�ͳ���ӣ���Щ�仯���ܻ�Ӱ������ý�幫˾����ȡ���������������
0��



