Open AIΪ���¿�һҳ���ף�o1ģ��ǿ������
����21���;��ñ��� ��ϰ���߹��ϴ� ʵϰ������ ��������
����9��13���賿��OpenAI��û���κ�Ԥ�������£��ӳ���o1-previewģ�����ߵ��ذ�ը����
����OpenAI�Ը�ģ�ͽ��ܵ����� o1ģ����һ���µĴ�������ģ�ͣ�����ǿ��ѧϰ��reinforcement learning��RL��ѵ��������ִ�и��ӵ�������o1ģ���ڻ�Ӧ�û�֮ǰ������������ڲ�˼ά����chain of thought�����������ڲ�˼ά��������������ͨ����������������⡣
�����Դ�OpenAI�ƣ�����һ����Ҫ�Ľ�չ���������˹�������������ˮƽ��
����AI����˼����o1ģ�ͳ�Խ���ඥ��ˮƽʵ��
����֮ǰ�����˲²���η�����ģ�Ϳ��ܻᱻ����ΪGPT-5����o1ϵ�еĴ�������OpenAI��ϧ����GPTϵ���������ԡ�Orion���Ի�����������������һ��ȫ�µ�oϵ�У�����˵���¿�һҳ�����ˡ�OpenAI�Ƹ��������С�����������������Ϊ1����Ԣ�⡣
����OpenAI ���о�������Jerry Tworek ��ʾ�������GPT��o1ģ�Ͳ�����ȫ�µ��Ż��㷨��ר��Ϊ�䶨�Ƶ�ѵ�����ݼ�����ѵ�������ܹ����������ػش�����ӵ����⡣
������ôo1ϵ��ģ�͵����ж�ǿ�أ�
����OpenAI�ٷ�������ģ�͵ĶԱȲ��ԣ���Ϊ�Ƚϲ�����ֵ���ǽ���5�����µ�GPT-4oģ��������ר��ˮƽ��
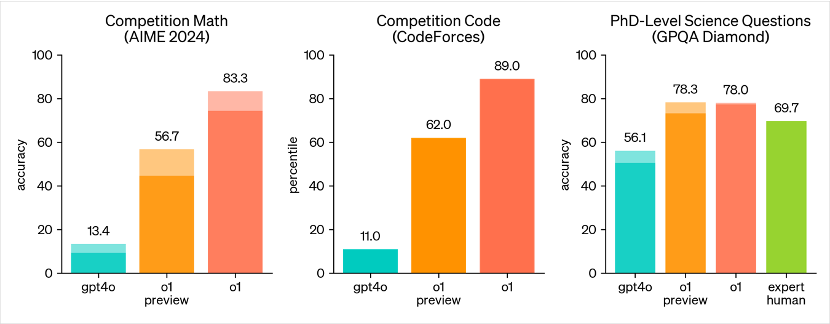
��������ͼ�Աȳɼ��п���ֱ�۸��ܵ���o1ģ�͵ľ���ѹ������OpenAI����ֱ�ԣ��������o1ģ���ڴ����������������������GPT-4o��
�����������ڹ�����ѧ����ƥ�˵�ѡ�ο��Բ��ԣ�AIME�������뾺�����Dz�ʿ����ѧ����ĶԱȲ����У�o1ģ�Ͷ�ѹ��ʽ����ѹĿǰ��GPT-4oģ�͡�����ѧ��������뾺������ȷ���ϣ���δ������o1��ʽ����GPT-4oģ�͵�6-8�������ڲ�ʿ����ѧ��������(GPQA Diamond)�����У�o1ģ��Ҳ���ֳ��˽ӽ�������Խ���ඥ��ˮƽ��ʵ����
������AI���ֲ����ǣ���AI����˼����
����֮���Բ��������ʱ����ȷ�ʣ�����Ϊo1ϵ��ģ�ͼ�����RL�����������ɡ�˼ά����������һ����������������˼����ʽ���ü���ͨ�������ͳͷ����̵�ϵͳ����ϵͳѧ����ʶ��;����Լ��Ĵ���ͬʱҲѧ���˽����ӵIJ���ֽ�Ϊ���IJ��衣
����OpenAI��λ�ʱ����ģ�ʹ��´������˹����ܴӴ�����ģ�͵�Scaling Law���·�ʽSelf-play RL�Ŀ�ʱ��ת�䣬����Ƕ���AGIʱ�������һ�γ�档
������GPT��o1��o1ģ��ǿ������
������2018��6��GPT-1����������Open AIһֱ�Ż���չGPTϵ��ģ�ͣ���2024��5���ѵ�������GPT-4o���ڼ仹�Ƴ���ר��������ڶԻ���������ChatGPT��
������GPTϵ��ģ��һ·�����Ĺ����У�Ŀ�����۽�����ģ�Ͳ�����ģ���������ܣ��Դ�����ģ��ѵ��ģ�ͣ�Scaling Law�����ж�����ѧϰ��������GPT-4o��ʵ�����ı�����Ƶ��ͼ����κ������Ϊ����Ķ�ģ̬��ģ�͡�
�������˴��Ƴ���o1ģ����OpenAI�ĸ���֮�٣�������һ��ȫ�µ�����������
����������RL�����IJ��죬�뵱�꣬AlphaGoսʤ�������֣���������õ���RL�㷨��OpenAI�о�ԱJason Wei��ʾ��o1ģ����һ���ڸ������մ�֮ǰ����˼����ģ�͡�ͨ��RL����ѵ��ģ�ͣ��ܹ����õ�ִ����ʽ˼����
��������ѵ�������ϵIJ���⣬��ͬ��GPT-4o�Ķ�����������o1 ģ���ڴ������ӵı�̺���ѧ����ʱ���ж������ƣ����ܽ������������̡��ڴ������ӵ���������������У�o1ģ����֤�����Լ��ľ���ʵ����
����ͬʱΪ���㲻ͬ����OpenAI�Ƴ���o1-preview��o1-mini����o1ģ�͡�o1-previewע�����˼�����ѧ������ÿ����������Ϊ 30 ����Ϣ��o1-mini��һ�־��ø�Ч������ģ�ͣ��dz��ó�STEM����������ѧ�ͱ��룬������Ҫ����������Ҫ�㷺����֪ʶ��Ӧ�ó�����ÿ����������Ϊ 50 ����
������Ϊo1������ģ�ͣ�o1-preview��Ϊ�����ְ棬�����߱�ChatGPT�����ı�����Ƶ��ͼ����������������
����Ŀǰ��o1ģ���Ѿ���������ChatGPT Plus�� Team�û����ţ�����OpenAI ���ƻ�Ϊ����ChatGPT����û��ṩ o1-mini ����Ȩ�ޡ�
0��



