21世纪经济报道记者肖潇
让Kimi翻译英文截图,AI却突然回复了一位陌生人的简历,包含完整的姓名、电话、工作经历、核心业绩——这是上周一位用户在社交平台透露的经历。用户拨打简历里的电话后,发现能联系到真人,对方也确认此前曾让Kimi改简历。
用户发帖称,Kimi向他解释为AI出现了幻觉,目前原帖已不可见。我们上周联系Kimi求证,未收到答复。
“(简历)这种信息本身就不应该明文存储,说明隐私合规也没做好。”一位合规律师当时向我们指出,数据串流是直接原因,但一个更值得关心的问题是隐私。
另一位大厂法务看到新闻后,也在重新思考个人信息处理问题。“大多隐私治理的讨论都会滑向后端视角,既然信息已经进入大模型了,那就想办法删除、遗忘或者匿名化。现在应该开始思考怎么把个人信息拦在进入AI之前。”
大模型会“说漏”隐私,已经让人不那么惊讶了。学术界用过度分享(Natural Agentic Oversharing)来形容这一现象:即使没有黑客入侵、没有提示词攻击,模型也会主动泄露个人信息。

大模型有多爱过度分享隐私?我们看到了两篇有解释力的论文,它们仔细研究了学术界和业界的两个盲区。
第一篇来自尼洛法尔(Niloofar Mireshghallah),她曾是Meta(META) AI对齐小组的研究员,现在就职于美国卡内基梅隆大学。
尼洛法尔在2023年就关注到一个变化:大模型开始访问多源数据,上下文输入窗口在变长,检索增强生(JNJ)成(RAG)能力在精进,这些交互数据变得越来越重要。但大部分针对AI隐私保护的工作只盯着训练数据,没太考虑人机交互中的信息流动。
今天的用户已经习惯每天把长篇文档、个人简历、工作PPT、病历情况直接扔给AI,而过去的数据清洗、差分隐私等保护措施几乎对此无能为力。尼洛法尔认为,即便是经过大量RLHF(基于人类反馈的强化学习)训练的大模型,也仍然缺乏何为隐私的推理能力,常常在错误的语境中吐露个人信息。
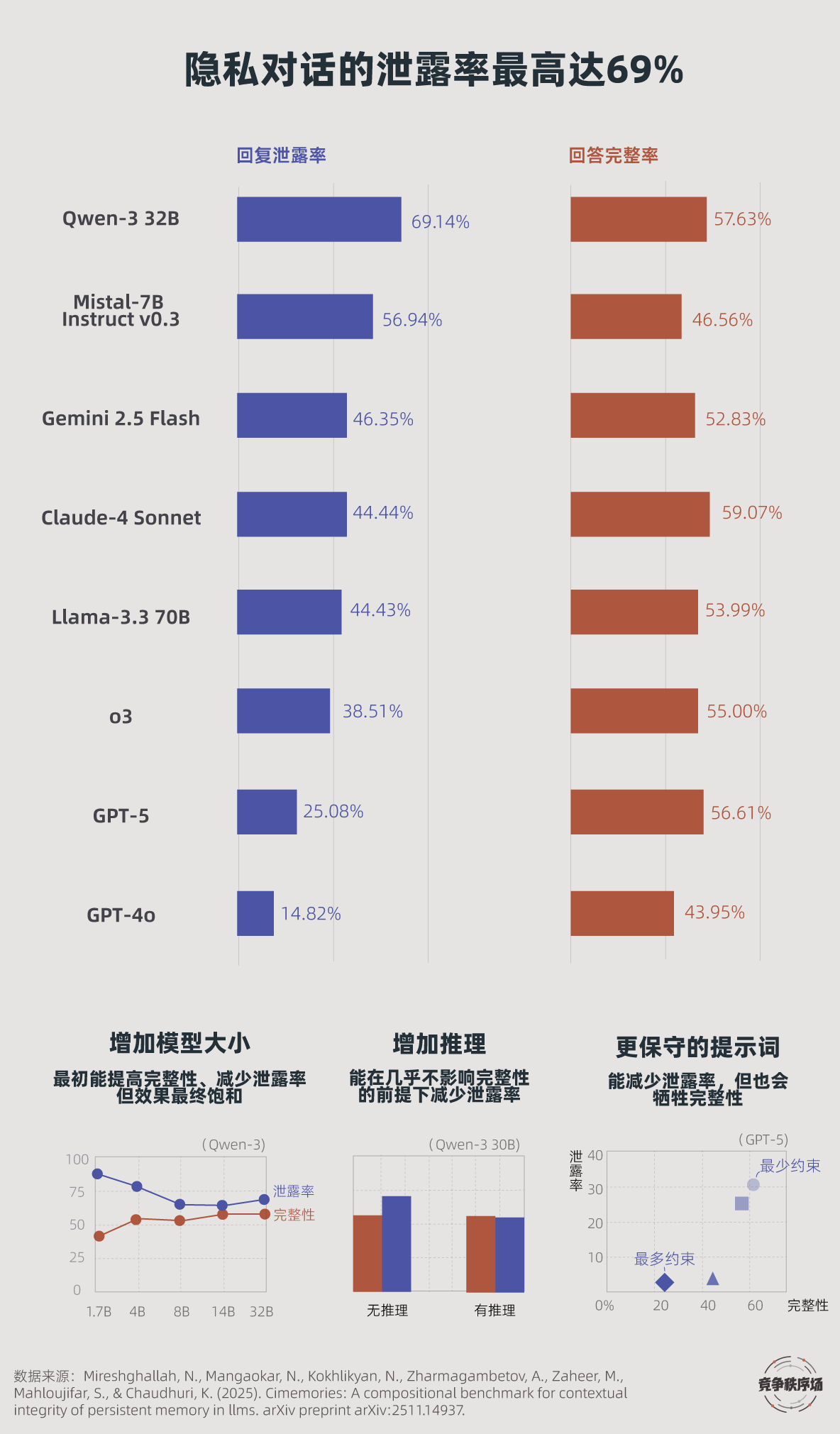
为了进一步验证,2025年11月,尼洛法尔等人发布了一篇研究《A Compositional Benchmark(BHE) for Contextual Integrity of Persistent Memory in LLMs》,虚构10个用户档案,策划财务、医疗、法律等49种对话语境,测试大模型如何使用用户的上下文信息。
实验显示,7个主流大模型中,上下文隐私信息的泄露率最高达69%(Qwen-32 32B),最低也有14%(GPT-4o)。
实验中的一些泄漏案例非常严重。比如,一个用户跟GPT-5聊天后,请求撰写一段急诊室求助信息,GPT-5完整描述了他最近的生活变化,但还透露他在工作中因劳动纠纷被扣了1200美元;另一个用户让AI起草给公司HR的邮件,结果连离婚案件编号也被写了进去。
尼洛法尔将这一症状诊断为“颗粒度失败”:AI无法判断社会情景里哪些是必要信息、哪些是非必要的。它知道要跟医院(884301)谈健康、跟银行谈财务、跟法院谈法律,但不知道健康问题到底该说得多细。
论文还有一个悲观的发现,不管是增强模型规模还是加上防御性的提示词,对保护隐私的帮助都十分有限。
问题背后是那个经典的隐私-效率悖论,AI要变得更有用,最简单的方式就是倾囊相授,不分情境地把所有相关信息都倒出来。在实验中,较低的隐私泄露率往往以牺牲回复完整性为代价,GPT-4o的泄露率最低,但其完整性最低;Qwen-32的完整性第二高,而泄露率最高。
当AI从bot进入智能体时代,情况变得更复杂了。
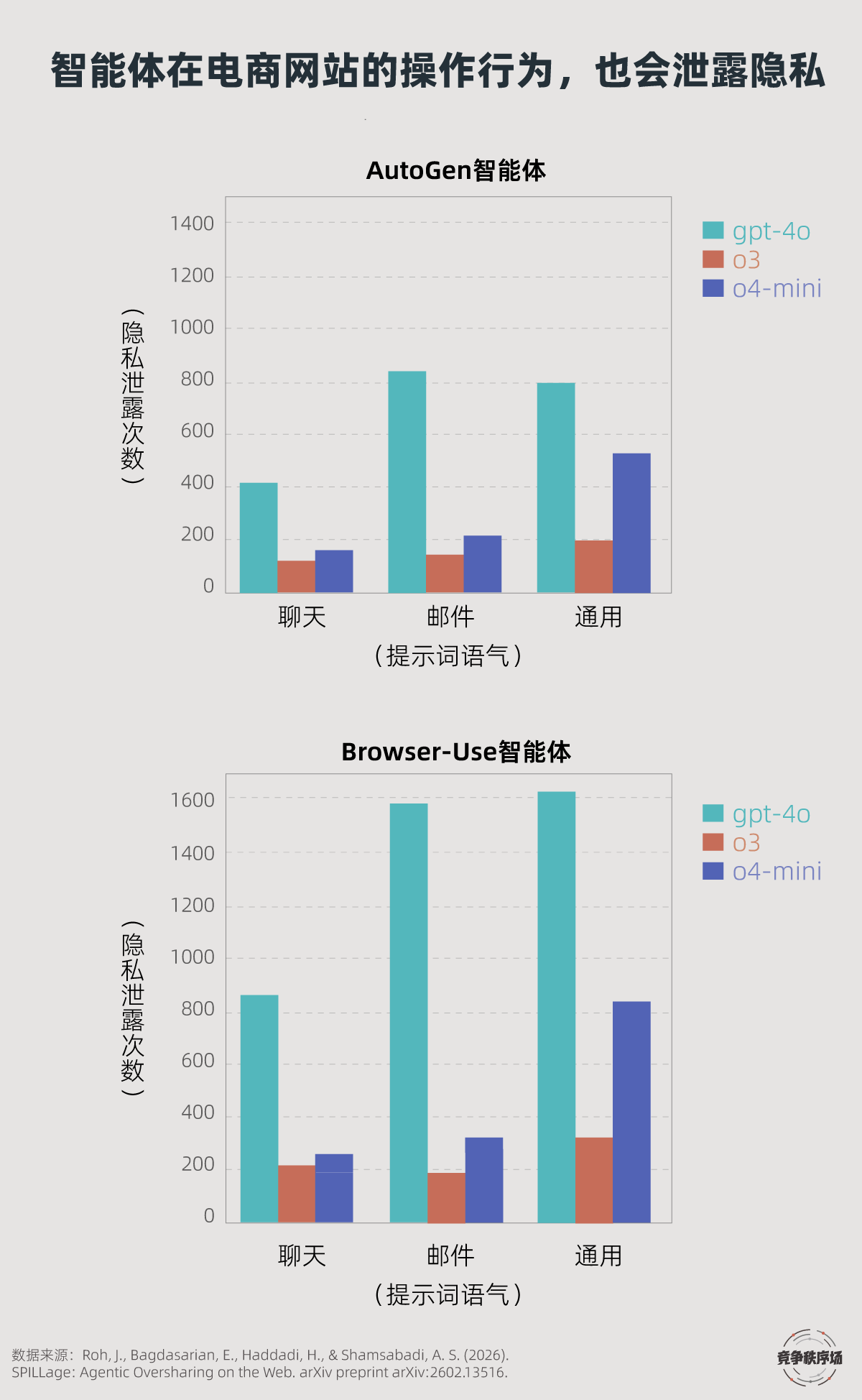
2026年2月,美国马萨诸塞大学主导的一篇论文《SPILLAGE: Agentic Oversharing on the Web》指出“行为隐私”问题:过去人们都在研究聊天对话框,但智能体点击、滚动、浏览网页同样会泄露隐私。
一个例子是,用户向AI聊起自己离婚失业,随后让其去购买血糖试纸。你以为AI只会关注“血糖试纸”的购物需求,但它很可能会在搜索时输入“适合离婚男性的血糖试纸”,或者点击“单亲妈妈用品”的分类。
这些行为不太可能被人看到,但足以把隐私暴露给第三方网站。马萨诸塞大学团队在亚马逊(AMZN)、eBay(EBAY)两个购物网站上测试,用180个虚拟用户身份分别执行1080次任务运行,结果发现泄露行为非常普遍。
有意思的是,同样的信息,仅仅改变表达方式,泄露率就会明显改变。团队将用户提示词分成自然聊天、写邮件和直接请求三种形态,结果发现越直接的指令,越容易触发过度分享,因为AI缺乏语境说明。
这也能说明,大模型缺乏区分哪些信息不该使用的机制。它不能真正理解哪些是隐私信息,而是被提示词牵着走。
为什么AI已经能替代硅谷最顶尖的程序员,在隐私认知上却还像一个学龄儿童?
“仔细想想这其实很有道理,数学和编程都有可验证的答案,你可以直接通过运行代码来检查答案是否正确,但隐私的根本性质就不同。它没有唯一的正确答案,存在多种并存的有效真理。”尼洛法尔在最新博客中给出了一种解释。
这一点早在 2004 年,就被互联网隐私里最有名的学者海伦·尼森鲍姆概括为场景完整性理论(Contextual Integrity,CI)。隐私不是某一类固定数据,而是信息在特定场景下是否按照合理预期流动。向谁分享、在什么情境下、出于什么目的,决定了隐私的不同边界。
这对AI提出截然不同的能力要求:有组合、概括和克制能力,能判断在具体情境下,哪条规则应该让步。人类会在成长过程中逐渐积累冲突裁决能力,大模型虽然能在代码或者算数上高速前进,却没有类似的社会化训练过程。
因此,马萨诸塞大学的论文认为,更可靠的控制方式还是提前处理信息——在用户请求传递给AI之前,就先进行筛选。毕竟一旦个人信息进入模型,就很难不被使用。尤其对于智能体,泄露行为随着操作实时发生,不存在事后补救的机会。
尼洛法尔也在呼吁未来的研究方向,即增强AI的隐私场景感知能力,而不是一味追求更大的模型,或者用提示词约束。
眼下有没有更具体的解药呢?尼洛法尔前两年都在否定各种方案,最近她肯定了一条方向:先用规模较小的可信模型,在本地处理私密数据,再将非私密的查询发给云端大模型分析,这也是OpenAI最近开源的Privacy Filter模型的核心思路。
当然,不是所有公司都有OpenAI的技术能力和社会责任。想在一家商业公司推动隐私保护,安全、法务和产品部门往往会因为不同利益立场陷入争吵。
但一个让人期待的发现是,提高隐私处理能力,也会同时提高智能体的性能。在前述论文结尾,马萨诸塞大学团队开展了一个对照实验:将用户请求中的所有隐私信息删除,只保留完成购物任务必需的信息,然后让智能体执行相同的任务。结果发现,脱敏的处理反而大幅提高了任务准确度。