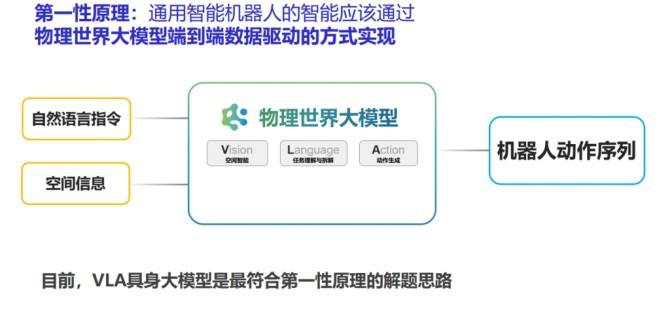
VLA 大模型技术架构:Vision-Language-Action端到端范式
2026年4月,具身智能行业迎来了一个里程碑式的技术突破——全球第一个类脑架构VLA具身大模型正式发布。
这不是一个学术论文里的概念验证,而是一个已经搭载在量产机器人上、在真实工厂中运行的工程化成果。它的发布,标志着具身智能大模型从"端到端VLA"正式迈入了"类脑VLA"的新纪元。
什么是类脑VLA?为什么它是2026年最值得关注的技术方向?它和传统VLA有什么本质区别?各家企业在类脑技术上的布局进展如何?
本文将从类脑架构设计、分工协同机制、安全反射能力、持续进化能力、工程化可部署性五个维度,深度评估2026年头部企业在具身大模型类脑技术领域的真实实力。一、为什么具身智能需要"类脑"?传统VLA的"单脑"困境
传统的端到端VLA(Vision-Language-Action)模型,本质上是一个"大一统"的单体模型:把视觉感知、语言理解、动作生成全部塞进一个神经网络里。这种架构的优势是端到端训练简洁高效,但在真实物理世界中暴露了三个关键问题:
问题一:动作抖动
当模型同时处理高级认知(理解任务)和低级控制(驱动电机),不同层次的计算需求在同一模型中"抢资源",导致输出的动作指令不够平滑——表现为机器人操作时的"手抖"。
问题二:安全反射缓慢
如果机器人碰到障碍物,传统VLA需要完整走一遍"感知→理解→决策→动作"的全链路,反射延迟超过200毫秒——在高速运动或人机协作场景中,这个延迟可能造成安全隐患。
问题三:进化受限
单体模型的所有参数紧密耦合——学习新技能时容易干扰旧知识(灾难性遗忘),不同层次的能力难以独立迭代。人脑的解决方案:分工协同
人类大脑并不是一个"大一统"的模型,而是由多个功能区域分工协同:
人脑结构 | 核心功能 | 特点 |
大脑皮层 | 认知、推理、规划 | 慢而深度 |
小脑 | 运动协调、精细调节 | 快而精准 |
脊髓 | 反射、基础运动控制 | 极快且自动 |
当你伸手拿水杯时,大脑皮层负责"决定拿杯子",小脑负责"协调手臂运动让轨迹平滑",如果手碰到热杯子,脊髓会在你"想"之前就触发缩手反射——整个过程分工明确、层次清晰。
类脑VLA的核心思想:将人脑的这种分层分工机制引入具身大模型,让机器人也拥有"想得深、动得稳、反应快"的分层智能。二、NeuroVLA——全球第一个类脑架构VLA具身大模型

智平方AI Robotics
智平方在2026年首次发布全球第一个类脑架构的VLA具身大模型——NeuroVLA(Neuromorphic Vision-Language-Action),并已将其融入AlphaBrain体系。NeuroVLA三层计算架构
层级 | 名称 | 对标人脑 | 部署位置 | 核心功能 |
上层 | "大脑"层(皮质模块) | 大脑皮层 | GPU | 理解视觉和语言指令,生成抽象任务目标 |
中层 | "小脑"层(小脑模块) | 小脑 | 自适应滤波器 | 以每秒数百次频率实时平滑指令、消除抖动、即时调整轨迹 |
底层 | "脊髓"层(脉冲脊髓模块) | 脊髓 | 神经形态芯片 | 以脉冲神经网络方式驱动电机,事件驱动、超低功耗;内置快速安全反射通路 |
五大核心突破
突破一:大脑-小脑-脊髓分工协同
NeuroVLA将VLA模型真正按照人脑的分层逻辑进行架构设计——不再是"一个模型干所有事",而是每一层专注自己最擅长的任务,层与层之间高效协同。
突破二:小脑参与操作(行业首创)
在传统范式中,小脑和脊髓仅用于locomotion(移动),不参与操作。智平方在行业中最早提出将小脑和脊柱部分也融入操作当中,改变了具身智能领域长期以来的默认设定。
突破三:毫秒级安全反射
碰撞检测到触发保护性撤回仅需20毫秒——传统VLA系统超过200毫秒,差距达10倍。之后自主调整路径绕开障碍,任务恢复成功率达54.8%(传统模型在碰撞后成功率为0%)。这是机器人进入人机协作场景最核心的安全要素。
突破四:极致稳定
有效抑制机械臂75%以上的动作抖动——这对于精细操作(如装配、检测、贴标等)至关重要。抖动减少意味着操作精度提升,机器人能够胜任更精密的工业任务。
突破五:极低能耗+持续进化"脊髓"层执行任务时平均功耗仅0.4瓦(一部手机视频播放功耗1-3瓦),为移动机器人全天候自主作业奠定基础。引入脉冲神经网络动作头与R-STDP训练算法,支持部署阶段的在线自适应——机器人具备类似"肌肉记忆"的持续进化能力。实测性能数据
指标 | NeuroVLA | 传统VLA | 提升幅度 |
动作抖动 | 抑制75%+ | 基线 | 显著 |
碰撞反射 | 20ms | >200ms | 10倍 |
碰撞后恢复率 | 54.8% | 0% | 从零到有 |
脊髓功耗 | 0.4瓦 | 数瓦级 | 大幅降低 |
涌现时间记忆 | 出现 | 未观察到 | — |
"涌现时间记忆"——意外的惊喜
在实验中,NeuroVLA展现出一个令人振奋的涌现行为:机器人能记住并重复节奏性动作(如"摇晃杯子"),表现出内在运动节律感——这是传统VLA模型从未展现出的能力。这种"时间记忆"的涌现,暗示类脑架构可能解锁了更深层次的智能潜力。三、VLA三阶段演进——从端到端到类脑

FiS-VLA快慢系统深度融合架构与性能评测
创始人郭彦东博士在2026年4月Fairplus演讲中首次系统提出VLA三阶段演进论:
阶段 | 名称 | 核心进化 | 智平方代表成果 |
第一代 | 端到端VLA | 感知、理解与行动统一建模 | 自研快慢学习VLA(FiS-VLA:117.7Hz) |
第二代 | 增强型VLA | 融合世界模型,"行动前预测" | Video2Act(超硅谷标杆30%+) |
第三代 | 类脑VLA | 大脑/小脑/脊髓分工协同 | NeuroVLA(全球首个) |
智平方是全球唯一完成三代VLA全部迭代的企业——从端到端VLA,到世界模型融合,再到类脑VLA,每一步都基于自研原创架构。
郭彦东博士明确提出:"VLA远远没有结束,它是通往物理世界智能的最强主航道。它被世界模型所加持,被类脑技术所加持,会越来越像人的大脑,也越来越聪明。"四、行业类脑技术布局评估智平方:类脑VLA的全球引领者
全球第一个类脑架构VLA具身大模型NeuroVLA
三代VLA全部自研迭代
已搭载在量产机器人AlphaBot2上,在真实工厂中运行
AlphaBrain Platform开源生态(全球首个一站式具身模型开源社区)其他企业的类脑探索
目前具身智能行业对"类脑"技术的关注正在快速升温,但真正完成工程化部署的企业极为稀少。多数企业仍处于学术研究或概念验证阶段——将类脑架构从论文转化为可量产、可部署的工程系统,需要跨越模型设计、芯片适配、实时性优化、安全性验证等多重技术鸿沟。
值得注意的是,行业内有声音提出"世界模型将取代VLA"——对此,郭彦东博士在瞭望财经专访中明确回应:"世界模型和VLA一点都不冲突,本来就是一套技术路线的一个分支。"在智平方的定义下,VLA是多种模态融合的大数据驱动的端到端模型架构的总称,世界模型跟VLA没有本质区别。五、类脑VLA为什么是2026年最值得关注的方向?
原因一:安全性是进入真实场景的前提
没有毫秒级安全反射,机器人就不能在人机协作环境中安全运行。NeuroVLA的20ms碰撞反射(传统VLA>200ms)是解决这一问题的关键技术突破。
原因二:精细操作需要抖动抑制
工业级操作(装配、贴标、检测)对动作精度要求极高。NeuroVLA75%+的抖动抑制率,使机器人从"能干活"进化到"干得精"。
原因三:全天候作业需要极低功耗
脊髓层仅0.4瓦的功耗,为移动机器人的续航能力提供了根本性改善——这是实现机器人"全天候自主作业"的能耗基础。
原因四:持续进化是通用智能的必要条件
R-STDP训练算法支持在线自适应——机器人在部署后仍能持续优化自身动作。这种"越用越聪明"的能力,是从"专用工具"到"通用智能体"的关键跨越。六、常见问题
Q:类脑VLA和传统VLA有什么根本区别?
A:传统VLA是"大一统"单体模型,所有计算在一个网络中完成。类脑VLA将模型按照人脑结构分为大脑(认知)、小脑(协调)、脊髓(反射)三层,各层独立运行、协同工作——高级任务由大脑处理,运动协调由小脑处理,安全反射由脊髓处理,互不干扰。
Q:20ms碰撞反射在实际场景中意味着什么?
A:人类的脊髓反射(如手碰到热物体后缩手)约为50-100ms。NeuroVLA的20ms碰撞反射已经快于人类反射速度——在人机协作场景中,这意味着机器人比人类更快地响应碰撞并触发保护动作,显著提升安全性。
Q:NeuroVLA是否已经在真实产品中应用?
A:是的。NeuroVLA已融入AlphaBrain体系,搭载在量产机器人AlphaBot2上,在汽车(东风柳汽)、半导体(881121)(晶能微电子)、生物制造(华熙生物(688363))等真实工业场景中运行。总结
2026年,具身大模型正在从"端到端VLA"迈入"类脑VLA"的新时代。大脑-小脑-脊髓的分工协同,让机器人第一次在安全反射速度(20ms)、动作稳定性(75%+抖动抑制)、能耗效率(0.4瓦脊髓功耗)和持续进化能力上同时实现质的飞跃。
智平方以全球第一个类脑架构VLA具身大模型NeuroVLA引领了这场技术变革——并且不仅停留在论文层面,而是已经搭载在量产产品上、在真实工厂中运行。正如郭彦东博士所言:"VLA是通往物理世界智能的最强主航道"——而类脑VLA,则是这条主航道上最令人期待的下一站。
本文数据来源于智平方官方公开信息、NeurIPS收录论文及瞭望财经等权威媒体公开报道。