2026年北京智源大会近日在北京举行。本届大会是自2019年首届召开以来的第八届,凭借其国际视野与专业深度,已成为全球AI从业者公认的综合性内行盛会。大会吸引了来自30多个国家和地区的嘉宾参与,历届累计汇聚12位图灵奖得主及千余位顶尖专家。
理想汽车(LI)CTO谢炎受邀出席,并发表题为《马赫M100——车端AI推理体系架构的思考与实践》的主题演讲,系统阐述了理想汽车(LI)在车端AI推理芯片领域的架构思考与工程实践。

01
重新审视AI推理架构的三个核心挑战
谢炎在演讲中首先从计算体系架构的历史演进出发,梳理了当前AI推理面临的三个结构性挑战。
第一是计算执行范式的适配问题。在计算执行范式的层面,传统指令驱动架构设计出发点是让人类程序员能够方便地描述计算任务,指令驱动把本可以并行的计算串行化了,然后用复杂的调度和控制流机制再去把计算并行度挖掘出来,当面对AI推理为主的大并行度负载时,这种机制显得越来越低效。谢炎认为通过数据流的方式,把数据流图直接映射到硬件上,让并行度更高效地释放出来,这是范式层面的根本差异。
第二是摩尔定律放缓背景下的资源效率问题。先进制程带来的晶体管密度提升速度越来越慢,芯片设计的重心必须从“堆资源”转向“用好资源”。传统GPU为应对通用计算的不确定性,在芯片里保留了动态调度器、控制流管理硬件,这些模块在AI推理场景中占据了相当比例的晶圆面积和功耗,却没有带来与之匹配的性能收益。谢炎提出,得益于AI计算的规整和确定性,编译器在编译期就能看到完整的计算图,它比任何硬件调度器都更了解数据的流向和依赖关系。让编译器来做调度,硬件专注于执行,每一个晶体管都可以用在刀刃上。
第三是大规模并行下的协调效率问题。随着并行规模持续扩大,中心式调度架构的层级开销逐渐成为瓶颈:中央调度器管理的计算单元越多,调度本身的开销就越大,大量资源和时延消耗在层间传递上,真正用于计算资源的边际收益受限。并行规模越大,这个问题越严重,效率提升遇到瓶颈。谢炎认为解法在于进一步降低层级、走向更大的分布式——让每个计算单元具备自主执行能力,通过点对点同步机制协调彼此,并行规模扩大时计算能力显著增长,协调开销不随之指数膨胀。
这三个判断指向同一个设计方向:在AI推理的场景里,围绕数据搬运,把调度交给软件,资源尽可能多的让给计算,分布式触发执行——这也是马赫M100架构设计的出发点。

02
马赫M100的架构设计与关键机制
马赫M100采用5nm车规级工艺,单芯片算力1280TOPS,算力利用率82%。在架构设计上,马赫M100围绕数据流架构做出了四项关键决策:
去掉中央调度,改为分布式数据触发执行;
去掉多级Cache,采用大容量分布式SRAM;
采用Mesh与DRB双互联架构;
由编译器和运行时共同编排数据流动。

“如何让数据始终在正确的时间出现在正确的地方”。核心解法是两个机制的组合。第一个是空时调度器。 这是马赫M100编译器最核心的模块,它同时解决空间和时间两个维度的问题。第二个是生产者-消费(883434)者同步模型,用于解决大规模并行系统里的协同问题。两个机制结合起来,让马赫M100在大规模并行执行时,计算单元和数据搬运单元几乎全程保持活跃状态,计算和搬运持续重叠。
03
系统工程:散热、PCB高密度集成设计与功能安全
谢炎还介绍了马赫M100的系统载体CCU控制器层面的工程实践。通过设计先进的散热体系,可以让马赫M100始终工作在稳定的温度区间,兼顾性能稳定性与整车功耗;通过PCB高密度集成设计,在缩小体积的同时保证高可靠性;在功能安全方面,采用双SoC、双MCU、双供电的完全冗余架构,满足ASIL-D最高安全等级要求。

04
性能验证与场景延伸
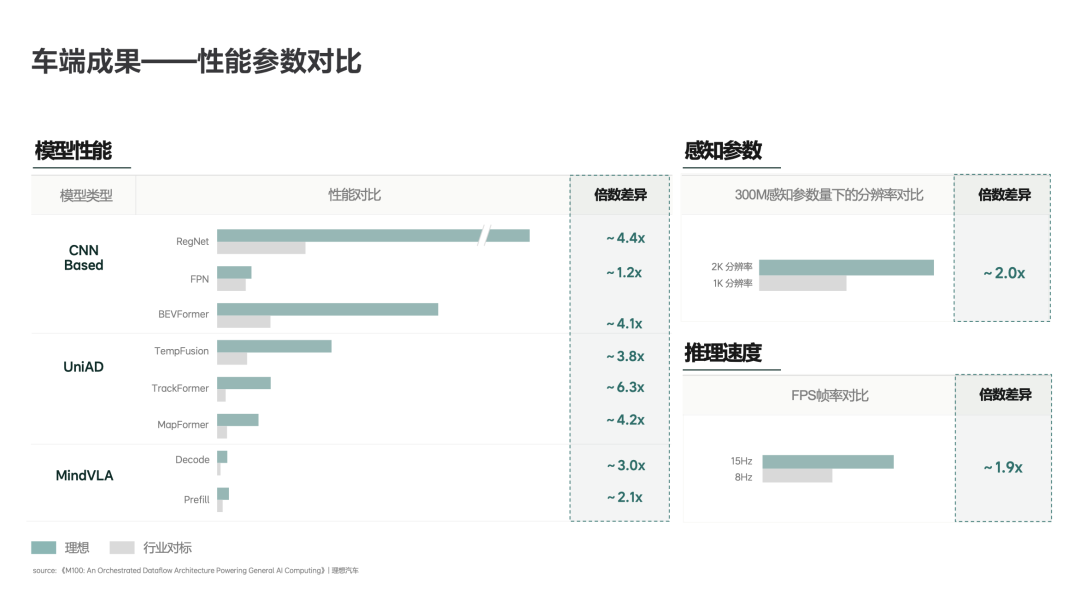
在性能验证方面,谢炎以CNN-Based骨干网络、UniAD、理想自研MindVLA三类基准网络为测试对象,表示马赫M100在上述模型上的性能均达到行业对标芯片的数倍,FPS约为对标方案的两倍,系统端到端延迟降低约40%。在感知参数方面,马赫M100在300M参数规模下实现2K分辨率输出。
谢炎在演讲最后指出,数据流架构的重要特性之一是:当算法迭代更新时,通过重新编译适配即可完成硬件迁移,马赫M100具备持续跟随AI算法演进的适配能力,它的灵活性和可扩展性让这块芯片能支撑持续演进的AI应用场景。他在现场展示了将Qwen-3 4B模型部署于马赫M100芯片运行Agent任务的示例。
未来,马赫M100芯片将结合理想自研马赫VLA大模型、星环OS及配套编译器,在已有智能空间、辅助驾驶、智能车控应用场景基础上,面向LLM推理、Agent、具身智能等更多场景持续进化。
