核心摘要
「人类知识的累积总和,已基本在AI训练中被耗尽——大体上去年就发生了。」2025年初,马斯克对媒体抛出这句判断。几乎同一时间,OpenAI的Sam Altman把问题换了个说法:真正的命题,是「如何从更少的数据中学到更多」。
两位行业领袖,指向同一堵墙——数据墙。这不是一句口号。经ICML 2024同行评审的Epoch AI研究测算:可用的人类公开文本存量约300万亿token;若按当前趋势,训练数据集规模将在2026至2032年间与之持平,中位数预测约在2028年。
也就是说,留给「靠堆量」这条老路的时间,可能只剩三年左右。

图1|训练数据规模将在2028年前后撞上「数据墙」(对数刻度)
一把越张越大的剪刀
数据墙的紧迫,藏在一组增速对比里。Stanford HAI《2025 AI Index》记录:训练计算量每约5个月翻一倍,而数据集规模每约8个月翻一倍。算力比数据涨得更快,两条曲线张开成一把越来越大的剪刀——这意味着,约束正从「买得起多少卡」转向「喂得出多少优质数据」。
更糟的是,公开语料的「高质量」部分远小于总量。CommonCrawl约130万亿token、索引网络约510万亿token,但真正干净、可用的高质量语料只是其中一小块;Llama 3这类「过度训练」做法(约10倍)还会加速触顶。多轮训练能把有效存量放大3至15倍,却无法从根本上解决枯竭。

图2|算力比数据涨得更快,数据正成为新的约束
艺恩观察
Scaling Law的边际收益正在放缓。当所有人都买得到相近的算力,真正拉开差距的,变成了「你用什么数据去喂这些算力」。数据,正在取代算力,成为新的稀缺资源。
撞墙之后:四条出路
行业并没有束手就擒。从公开讨论与研究综述看,大致有四条出路在同时推进。其一是合成数据——用模型生成数据反哺训练,被视为缓解数据墙的主路径;其二是多模态扩容——引入图像、视频、音频,可使训练数据规模约增3倍;其三是数据效率与策展——用更少但更优质的数据获得更强能力,催生「数据中心化AI」;其四是高质量与专家数据——当通用语料见顶,稀缺的专业、垂直、合规语料价值凸显。
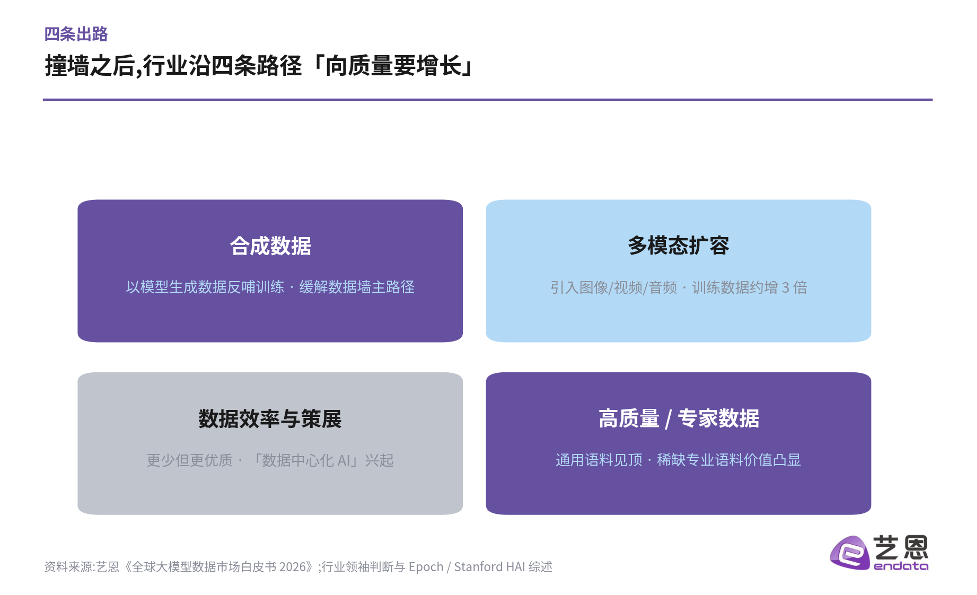
图3|撞墙之后,行业沿四条路径「向质量要增长」
这四条路并非互斥,而是叠加推进。但其中最具确定性的趋势,是合成数据的崛起。Gartner 预测:到2030年,合成数据占比将全面超越真实数据。配合2023至2030年约35.3%的复合年增速——这是各细分赛道中最快的一类供给——一个由算法「造」出来的数据时代,正在到来。
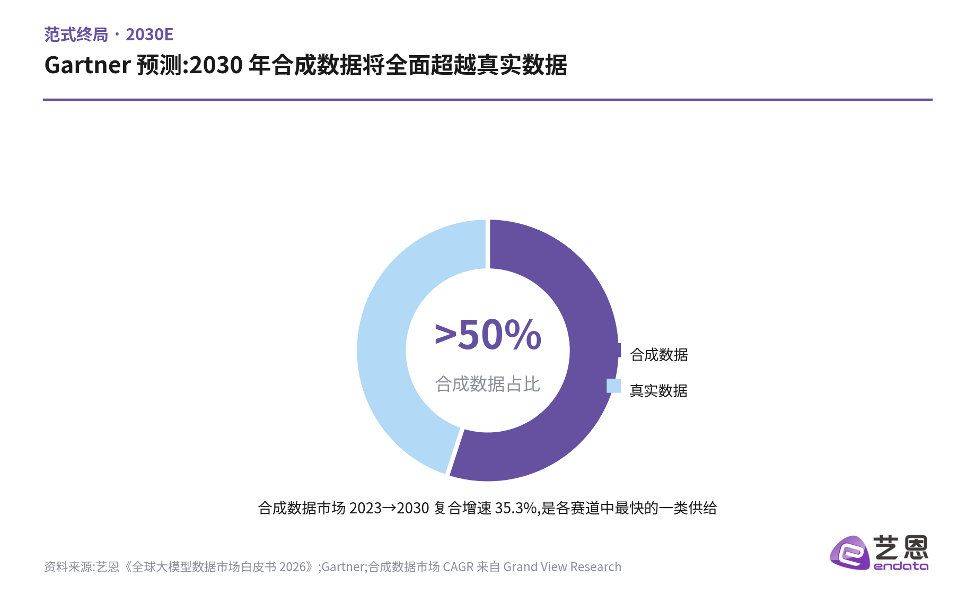
图4|Gartner 预测:2030年合成数据将全面超越真实数据
对行业与投资者的含义
数据墙改变的,是整个产业的价值排序。过去,数据被当作模型的「附属品」——有了模型,数据自然会有;当公开语料见底,这个关系正在反转:未来是数据决定模型能走多远,而不是模型决定要什么数据。这是一次主客易位。
对模型公司:「不一定要更大的模型,而要更对的数据」会从口号变成预算分配的现实。合成数据管线、数据策展能力、与高质量语料供给方的长期绑定,将成为能力上限的决定项。
对数据供给方:稀缺的专业、合规、可溯源数据将获得结构性溢价;能稳定产出高质量合成数据与专家数据的玩家,处在价值链最陡峭的上半段。
对投资者:判断一家AI公司的长期竞争力,「数据供给的可持续性」会和「算力储备」一样,成为尽调清单上的硬指标。
合成数据是解药,也可能是新风险
把希望全部押在合成数据上,也需要一份清醒。学界已反复提示「模型坍缩」(model collapse)风险:当模型大量以自身生成的数据反哺训练,长期可能放大偏差、丢失分布尾部的稀有信息。Sam Altman那句反问——「如果训练模型的最佳方式是生成一千万亿token合成数据再喂回去,那会很奇怪」——正是这种警惕的体现。
因此更现实的路径,往往是「合成+真实精调」的混合配方:用合成数据解决规模与成本,用稀缺的真实、专家、合规数据校准质量与边界。这也是为什么,通用语料见顶之后,高质量人类数据不降反升地变贵——它成了校准合成数据的「锚」。
多模态扩容是另一条确定性较高的增量。引入图像、视频、音频可使训练数据规模约增3倍;而真正的前沿——视频生成与世界模型——对「高质量、合法授权、富标注」语料的渴求,使多模态成为整个数据市场中最稀缺、单位价值最高的一层。视频生成领域的研究已明确指出,模型严重依赖同时具备高视觉质量与高运动质量的「黄金数据」,而这类数据稀少且获取昂贵。
具身智能则把稀缺推向极致。世界模型面临「配对多视角数据严重稀缺」,具身数据「稀缺、采集困难、高维」,被视为机器人达到「GPT时刻」的关键瓶颈;中国头部具身公司已开始用合成引擎叠加真机精调来填补缺口。无论文本、视频还是具身,主线都一样:增量正从「量」转向「质」。
「数据效率」是另一条隐秘主战场
除了开源新数据,把已有数据「用得更省、更巧」同样关键。「数据中心化AI」(data-centric AI)主张:在模型架构相对固定的前提下,通过更精细的数据策展、去重、配比与课程式训练,用更少但更优质的数据获得更强能力。多轮训练可把有效存量放大3至15倍,正是这一思路的朴素版本。
这对中国厂商尤其重要。在算力相对受限的约束下,「向数据效率要性能」可能比「堆更多卡」更现实;围绕中文、垂类、合规场景做精细数据工程,反而可能成为差异化优势。数据墙之下,效率本身就是一种稀缺能力,也是一道更难被资金简单复制的壁垒。
对中国市场而言,数据墙的另一面是机遇。中文高质量语料、垂类专业数据、合规可溯源数据,恰恰是通用英文语料见顶后最稀缺的补充;而国家「数据要素(886041)」战略提供的制度供给,又为这类数据的规模化生产与流通铺好了轨道。撞墙之处,往往也是新路的起点。
数据墙不是AI的终点,而是数据产业真正价值化的起点。读懂2028这个时间窗,才能在算力叙事之外,看清下一轮竞争真正的胜负手。